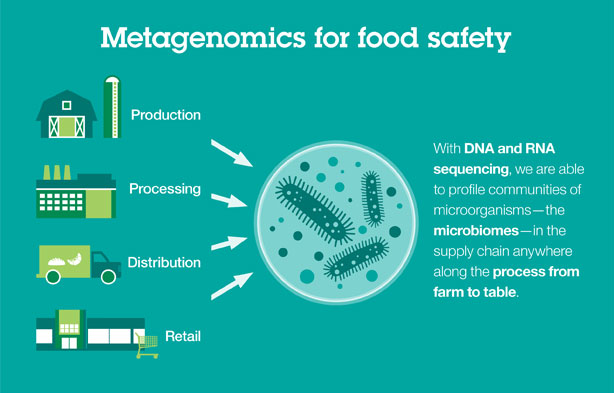
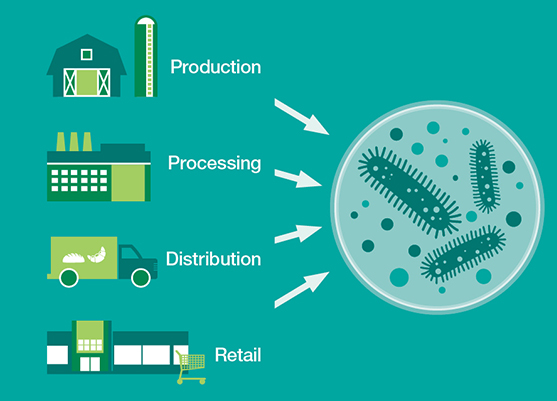
Americans consume an estimated 600 pounds of milk and milk-based products annually, according to the USDA. In an effort to minimize the hazards in the milk supply and prevent food fraud, IBM Research and Cornell University are joining forces. Combining next-generation sequencing with bioinformatics, the research project will collect genetic data from the microbiome of raw milk samples in a real-world situation at the Cornell University dairy plant and farm in Ithaca, New York.
Specifically, IBM and Cornell will sequence and analyze the DNA and RNA of food microbiomes, which will serve as a raw milk baseline, to develop tools that monitor raw milk and detect abnormalities that could indicate safety hazards and potential fraud. The data collected may also be used to expand existing bioinformatics analytical tools used by the Consortium for Sequencing the Food Supply Chain, a project that was launched by IBM Research and Mars, Inc. at the beginning of 2015.
“As nature’s most perfect food, milk is an excellent model for studying the genetics of food. As a leader in genomics research, the Department of Food Science expects this research collaboration with IBM will lead to exciting opportunities to apply findings to multiple food products in locations worldwide.” – Martin Wiedmann, Gellert Family Professor in Food Safety, Cornell University.
“Characterizing what is ‘normal’ for a food ingredient can better allow the observation of when something goes awry,” said Geraud Dubois, director of the Consortium for Sequencing the Food Supply Chain, IBM Research – Almaden, in a press release. “Detecting unknown anomalies is a challenge in food safety and serious repercussions may arise due to contaminants that may never have been seen in the food supply chain before.”
Cornell University is the first academic institution to join the Consortium for Sequencing the Food Supply Chain.
Using electronic retail scanner data from grocery stores, IBM Research scientists may have found a faster way to narrow down the potential source food contamination during an outbreak. Researchers from the firm conducted a study in which they were able to show that, using just 10 medical exam reports of foodborne illness, it is possible to pinpoint an investigation to 12 food products of interest in a only a few hours. A typically investigation ranges from weeks to months.
The study, “From Farm to Fork: How Spatial-Temporal Data can Accelerate Foodborne Illness Investigation in a Global Food Supply Chain”, demonstrated a new way to accelerate an outbreak investigation. Researchers reviewed the spatio-temporal data (i.e., geographic location and potential time of consumption) of hundreds of grocery products, and analyzed each product for shelf life, consumption location and the probability that the product harbored a pathogen. This information was then mapped to the known location of outbreaks.
“When there’s an outbreak of foodborne illness, the biggest challenge facing public health officials is the speed at which they can identify the contaminated food source and alert the public,” said Kun Hu, public health research scientist, IBM Research – Almaden in a press release. Rsearchers created a system to devise a list that ranked products based on likelihood of contamination, which would allow health officials to test the top 12 suspected foods. “While traditional methods like interviews and surveys are still necessary, analyzing big data from retail grocery scanners can significantly narrow down the list of contaminants in hours for further lab testing. Our study shows that big data and analytics can profoundly reduce investigation time and human error and have a huge impact on public health,” said Hu.
The researchers point of out their method isn’t a substitute for proven outbreak investigation tools but rather serves as a faster way to identify contaminated product(s). According to the study, researchers assert that their methodology could significantly reduce the costs associated with foodborne illness, outbreaks and recalls. Thus far IBM Research’s approach has been applied to a Norweigan E. coli outbreak in which there were 17 confirmed cases of infection. Public health officials used the method to devise a list of 10 potential contaminants from the grocery scanner data of more than 2600 products. From there, lab analysis traced the contamination source to batch and lot numbers of sausage.
The study was published in the Association for Computing Machinery’s Sigspatial Journal.
When it comes to preventing foodborne illness, staying ahead of the game can be an elusive task. In light of the recent outbreaks affecting Chipotle (norovirus, Salmonella, E. coli) and Dole’s packaged salad (Listeria), having the ability to identify potentially deadly outbreaks before they begin (every time) would certainly be the holy grail of food safety.
One year ago IBM Research and Mars, Inc. embarked on a partnership with that very goal in mind. They established the Consortium for Sequencing the Food Supply Chain, which they’ve touted as “the largest-ever metagenomics study…sequencing the DNA and RNA of major food ingredients in various environments, at all stages in the supply chain, to unlock food safety insights hidden in big data”. The idea is to sequence metagenomics on different parts of the food supply chain and build reference databases as to what is a healthy/unhealthy microbiome, what bacteria lives there on a regular basis, and how are they interacting. From there, the information would be used to identify potential hazards, according to Jeff Welser, vice president and lab director at IBM Research–Almaden.
“Obviously a major concern is to always make sure there’s a safe food supply chain. That becomes increasingly difficult as our food supply chain becomes more global and distributed [in such a way] that no individual company owns a portion of it,” says Welser. “That’s really the reason for attacking the metagenomics problem. Right now we test for E. coli, Listeria, or all the known pathogens. But if there’s something that’s unknown and has never been there before, if you’re not testing for it, you’re not going to find it. Testing for the unknown is an impossible task.” With the recent addition of the diagnostics company Bio-Rad to the collaborative effort, the consortium is preparing to publish information about its progress over the past year. In an interview with Food Safety Tech, Welser discusses the consortium’s efforts since it was established and how it is starting to see evidence that using microbiomes could provide insights on food safety issues in advance.
Food Safety Tech:What progress has the Consortium made over the past year?
Jeff Welser: For the first project with Mars, we decided to focus around pet food. Although they might be known for their chocolates, at least half of Mars’ revenue comes from the pet care industry. It’s a good area to start because it uses the same food ingredients as human food, but it’s processed very differently. There’s a large conglomeration of parts in pet food that might not be part of human food, but the tests for doing the work is directly applicable to human food. We started at a factory of theirs and sampled the raw ingredients coming in. Over the past year, we’ve been establishing whether we can measure a stable microbiome (if we measure day to day, the same ingredient and the same supplier) and [be able to identify] when something has changed.
At a high level, we believe the thesis is playing out. We’re going to publish work that is much more rigorous than that statement. We see good evidence that the overall thesis of monitoring the microbiome appears to be viable, at least for raw food ingredients. We would like to make it more quantitative, figure out how you would actually use this on a regular basis, and think about other places we could test, such as other parts of the factory or machines.
Sequencing the food supply chain. Click to enlarge infographic (Courtesy of IBM Research)
FST: What are the steps to sequencing a microbiome?
Welser: A sample of food is taken into a lab where a process breaks down the cell walls to release the DNA and RNA into a slurry. A next-generation sequencing machine identifies every snippet of DNA and RNA it can from that sample, resulting in huge amounts of data. That data is transferred to IBM and other partners for analysis of the presence of organisms. It’s not a straightforward calculation, because different organisms often share genes or have similar snippets of genes. Also, because you’ve broken everything up, you don’t have a full gene necessarily; you might have a snippet of a gene. You want to look at different types of genes and different areas to identify bad organisms, etc. When looking at DNA and RNA, you want to try to determine if an organism is currently active.
The process is all about the analysis of the data sequence. That’s where we think it has a huge amount of possibility, but it will take more time to understand it. Once you have the data, you can combine it in different ways to figure out what it means.
FST: Discuss the significance of the sequencing project in the context of recent foodborne illness outbreaks. How could the information gleaned help prevent future outbreaks?
Welser: In general, this is exactly what we’re hoping to achieve. Since you test the microbiome at any point in the supply chain, the hope is that it gives you much better headlights to a potential contamination issue wherever it occurs. Currently raw food ingredients come into a factory before they’re processed. If you see the problem with the microbiome right there, you can stop it before it gets into the machinery. Of course, you don’t know whether it came in the shipment, from the farm itself, etc. But if you’re testing in those places, hopefully you’ll figure that out as early as possible. On the other end, when a company processes food and it’s shipped to the store, it goes onto the [store] shelves. It’s not like anyone is testing on a regular basis, but in theory you could do testing to see if the ingredient is showing a different microbiome than what is normally seen.
The real challenge in the retail space is that today you can test anything sitting on the shelves for E. coli, Listeria, etc.— the [pathogens] we know about. It’s not regularly done when [product] is sitting on the shelves, because it’s not clear how effectively you can do it. It still doesn’t get over the challenge of how best to approach testing—how often it needs to be done, what’s the methodology, etc. These are all still challenges ahead. In theory, this can be used anywhere, and the advantage is that it would tell you if anything has changed [versus] testing for [the presence of] one thing.
FST: How will Bio-Rad contribute to this partnership?
Welser: We’re excited about Bio-Rad joining, because right now we’re taking samples and doing next-generation sequencing to identify the microbiome. It’s much less expensive than it used to be, but it’s still a fairly expensive test. We don’t envision that everyone will be doing this every day in their factory. However, we want to build up our understanding to determine what kinds of tests you would conduct on a regular basis without doing the full next-gen sequencing. Whenever we do sequencing, we want to make sure we’re doing the other necessary battery of tests for that food ingredient. Bio-Rad has expertise in all these areas, and they’re looking at other ways to advance their testing technology into the genomic space. That is the goal: To come up with a scientific understanding that allows us to have tests, analysis and algorithms, etc. that would allow the food industry to monitor on a regular basis.
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookies
Strictly Necessary Cookies should be enabled at all times so that we can save your preferences for these cookie settings.
We use tracking pixels that set your arrival time at our website, this is used as part of our anti-spam and security measures. Disabling this tracking pixel would disable some of our security measures, and is therefore considered necessary for the safe operation of the website. This tracking pixel is cleared from your system when you delete files in your history.
We also use cookies to store your preferences regarding the setting of 3rd Party Cookies.
If you visit and/or use the FST Training Calendar, cookies are used to store your search terms, and keep track of which records you have seen already. Without these cookies, the Training Calendar would not work.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.
Cookie Policy
A browser cookie is a small piece of data that is stored on your device to help websites and mobile apps remember things about you. Other technologies, including Web storage and identifiers associated with your device, may be used for similar purposes. In this policy, we say “cookies” to discuss all of these technologies.
Our Privacy Policy explains how we collect and use information from and about you when you use This website and certain other Innovative Publishing Co LLC services. This policy explains more about how we use cookies and your related choices.
How We Use Cookies
Data generated from cookies and other behavioral tracking technology is not made available to any outside parties, and is only used in the aggregate to make editorial decisions for the websites. Most browsers are initially set up to accept cookies, but you can reset your browser to refuse all cookies or to indicate when a cookie is being sent by visiting this Cookies Policy page. If your cookies are disabled in the browser, neither the tracking cookie nor the preference cookie is set, and you are in effect opted-out.
In other cases, our advertisers request to use third-party tracking to verify our ad delivery, or to remarket their products and/or services to you on other websites. You may opt-out of these tracking pixels by adjusting the Do Not Track settings in your browser, or by visiting the Network Advertising Initiative Opt Out page.
You have control over whether, how, and when cookies and other tracking technologies are installed on your devices. Although each browser is different, most browsers enable their users to access and edit their cookie preferences in their browser settings. The rejection or disabling of some cookies may impact certain features of the site or to cause some of the website’s services not to function properly.
Individuals may opt-out of 3rd Party Cookies used on IPC websites by adjusting your cookie preferences through this Cookie Preferences tool, or by setting web browser settings to refuse cookies and similar tracking mechanisms. Please note that web browsers operate using different identifiers. As such, you must adjust your settings in each web browser and for each computer or device on which you would like to opt-out on. Further, if you simply delete your cookies, you will need to remove cookies from your device after every visit to the websites. You may download a browser plugin that will help you maintain your opt-out choices by visiting www.aboutads.info/pmc. You may block cookies entirely by disabling cookie use in your browser or by setting your browser to ask for your permission before setting a cookie. Blocking cookies entirely may cause some websites to work incorrectly or less effectively.
The use of online tracking mechanisms by third parties is subject to those third parties’ own privacy policies, and not this Policy. If you prefer to prevent third parties from setting and accessing cookies on your computer, you may set your browser to block all cookies. Additionally, you may remove yourself from the targeted advertising of companies within the Network Advertising Initiative by opting out here, or of companies participating in the Digital Advertising Alliance program by opting out here.