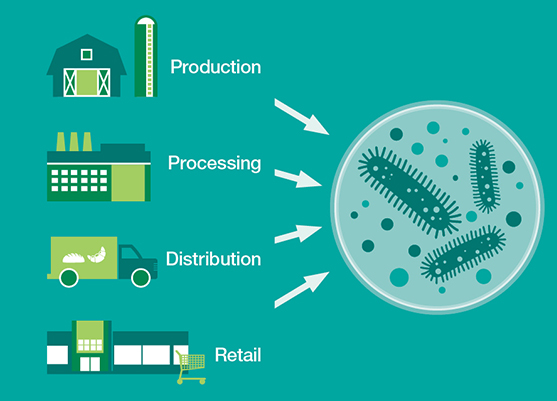
It’s not that the industry has been more reluctant than others to embrace change; rather, the forces that will drive the food’s big data revolution have but recently come to bear.
Regulation is now playing a role. FSMA mandates that the industry embrace proactive food safety measures. That means higher testing volumes. Higher testing volumes means more data.
At the same time, new technologies like next-generation sequencing (NGS) are beginning to find wide-scale adoption in food-safety testing. And NGS technologies generate a lot of data—so much so that the food safety lab will soon emerge as the epicenter of the food industry’s big data revolution. As a result, the microbiology lab, a cost center, will soon emerge as one the industry’s most surprising profit centers.
A Familiar Trend
This shift may be unprecedented in food, but plenty of other industries touched by a technological transformation have undergone a similar change, flipping the switch from overhead to revenue generation.
Take the IT department, for instance. The debate about IT departments being a cost or profit center has been ongoing for many years. If data centers had simply kept doing what they have done in the past—data processing, enterprise resource planning, desktop applications, help desk—maintaining an IT department would have remained a cost center.
But things look quite different today. Companies in today’s fast-changing business environment depend on their IT departments to generate value. Now and for the foreseeable future, the IT department is on the hook to provide companies with a strategic advantage and to create new revenue opportunities.
Netflix, for example, recently estimated the value of their recommenders and personalization engines at $1 billion per year by quadrupling their effective catalog and dramatically increasing customer engagement and reducing churn.
Another great example are the call centers of customer support departments. For most of their history, call centers generated incredibly small margins or were outright cost centers.
Now, call centers armed with AI and chatbots are a source of valuable customer insights and are a treasure trove of many brands’ most valuable data. This data can be used to fuel upsells, inform future product development, enhance brand loyalty, and increase market share.
Take Amtrak as a prime example. When the commuter railway implemented natural language chatbots on their booking site, they generated 30% more revenue per booking, saved $1 million in customer service email costs, and experienced an 8X return on investment.
These types of returns are not out of reach for the food industry.
The Food Data Revolution Starts in the Lab
The microbiology lab will be the gravitational center of big data in the food industry. Millions of food samples flow in and out of these labs every hour and more and more samples are being tested each year. In 2016 the global food microbiology market totaled 1.14 billion tests—up 15% from 2013.1
I’d argue that the food-testing lab is the biggest data generator in the entire supply chain. These labs are not only collecting molecular data about raw and processed foods but also important inventory management information like lot numbers, brand names and supplier information, to name a few.
As technologies like NGS come online, the data these labs collect will increase exponentially.
NGS platforms have dramatically reduced turnaround times and achieve higher levels of accuracy and specificity than other sequencing platforms. Unlike most PCR and ELISA-based testing techniques, which can only generate binary answers, NGS platforms generate millions of data points with each run. Two hundred or more samples can be processed simultaneously at up to 25 million reads per sample.
With a single test, labs are able to gather information about a sample’s authenticity (is the food what the label says it is?); provenance (is the food from where it is supposed to be from?); adulterants (are there ingredients that aren’t supposed to be there?); and pathogen risk.
The food industry is well aware that food safety testing programs are already a worthwhile investment. Given the enormous human and financial costs of food recalls, a robust food-safety testing system is the best insurance policy any food brand can buy.
The brands that understand how to leverage the data that microbiology labs produce in ever larger quantities will be in a position to transform the cost of this insurance policy into new revenue streams.
Digitizing the Food Supply Chain
It’s clear that the food lab will generate massive amounts of data in the future, and it’s easy to see that this data will have value, but how, exactly, can food brands turn their data into revenue streams?
The real magic starts to happen when we can combine and correlate the trillions of data points we’re gathering from new forms of testing like NGS, with data already being collected, whether for inventory management, supply chain management, storage and environmental conditions, downstream sales data, or other forms of testing for additives and contaminant like pH, antibiotics, heavy metals and color additives.
When a food brand has all of this data at their fingertips, they can start to feed the data through an artificial intelligence platform that can find patterns and trends in the data. The possibilities are endless, but some insights you could imagine are:
- When I procure raw ingredient A from supplier B and distributors X, Y, and Z, I consistently record higher-than-average rates of contamination.
- Over the course of a fiscal year Supplier A’s product, while a higher cost per pound, actually increases my margin because, on average, it confers a greater nutritional value than the supplier B’s product.
- A rare pathogen strain is emerging from suppliers who used the same manufacturing plant in Arizona.
Based on this information about suppliers, food brands can optimize their supplier relationships, decrease the risk associated with new suppliers, and prevent potential outbreaks from rare or emerging pathogen threats.
But clearly the real promise for revenue generation is in leveraging food data to inform R&D, and creating a tighter food safety testing and product development feedback loop.
The opportunity to develop new products based on insights generated in the microbiology lab are profound. This is where the upside lives.
For instance, brands could correlate shelf life with a particular ingredient or additive to find new ways of storing food longer. We can leverage data collected across a product line or multiple product lines to create new ingredient profiles that find substitutes for or eliminate unhealthy additives like corn syrup.
One of the areas I’m most excited about is personalized nutrition. With microbiome data collected during routine testing, we could develop probiotics and prebiotics that promote healthy gut flora, and eventually are even tailored to the unique genetic profile of individual shoppers. The holistic wellness crowd has always claimed that food is medicine; with predictive bioinformatic models and precise microbiome profiles, we can back up that claim scientifically for the first time.
Insights at Scale
Right now, much of the insight to be gained from unused food safety testing data requires the expertise of highly specialized bioinformaticians. We haven’t yet standardized bioinformatic algorithms and pipelines—that work is foundational to building the food genomics platforms of the future.
In the near future these food genomics platforms will leverage artificial intelligence and machine learning to automate bioinformatic workflows, dramatically increasing our ability to analyze enormous bodies of data and identify macro-level trends. Imagine the insights we could gain when we combine trillions of genomic data points from each phase in the food safety testing process—from routine pathogen testing to environmental monitoring to strain typing.
We’re not there yet, but the technology is not far off. And while the path to adoption will surely have its fair share of twists and turns, it’s clear that the business functions of food safety testing labs and R&D departments will grow to be more closely integrated than ever before.
In this respect the success of any food safety program will depend—as it always has—not just on the technology deployed in labs, but on how food brands operate. In the food industry, where low margins are the norm, brands have long depended on efficiently managed operations and superb leadership to remain competitive. I’m confident that given the quality and depth of its human resources, the food industry will be prove more successful than most in harnessing the power of big data in ways that truly benefit consumers.
The big data revolution in food will begin in the microbiology lab, but it will have its most profound impact at the kitchen table.
References
- Ferguson, B. (February/March 2017). “A Look at the Microbiology Testing Market.” Food Safety Magazine. Retrieved from https://www.foodsafetymagazine.com/magazine-archive1/februarymarch-2017/a-look-at-the-microbiology-testing-market/.